BASICS: How do I change processor counts and component layouts on processors?
This example modifies the PE layout for our original run, EXAMPLE_CASE. We now target the model to run on the yellowstone supercomputer and modify our PE layout to use a common load balanced configuration for CESM on large IBM machines. Also see the Section called Changing the PE layout in Chapter 2.
In our original example, EXAMPLE_CASE, we used 128 pes with each component running sequentially over the entire set of processors.
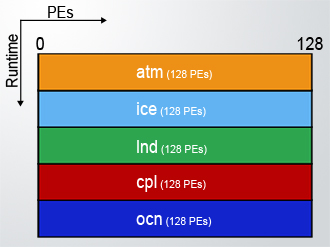
128-pes/128-tasks layout
Now we change the layout to use 1728 processors and run the ice, lnd, and cpl models concurrently on the same processors as the atm model while the ocean model will run on its own set of processors. The atm model will be run on 1664 pes using 832 MPI tasks each threaded 2 ways and starting on global MPI task 0. The ice model is run using 320 MPI tasks starting on global MPI task 0, but not threaded. The lnd model is run on 384 processors using 192 MPI tasks each threaded 2 ways starting at global MPI task 320 and the coupler is run on 320 processors using 320 MPI tasks starting at global MPI task 512. The ocn model uses 64 MPI tasks starting at global MPI task 832.
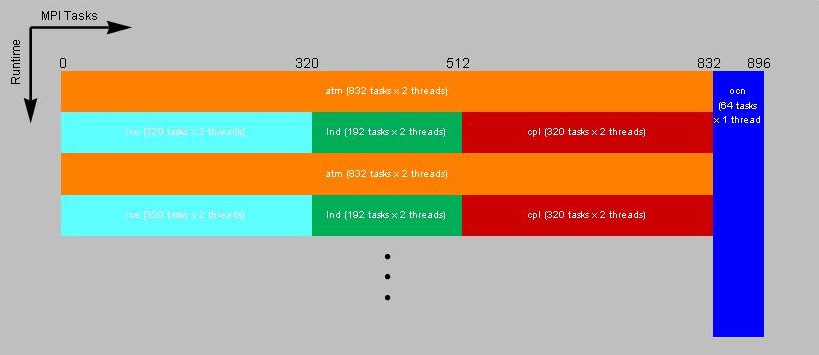
1728-pes/896-tasks layout
Since we will be modifying env_mach_pes.xml after cesm_setup was called, the following needs to be invoked:
> ./cesm_setup -clean > xmlchange NTASKS_ATM=832 > xmlchange NTHRDS_ATM=2 > xmlchange ROOTPE_ATM=0 > xmlchange NTASKS_CPL=320 > xmlchange NTHRDS_CPL=1 > xmlchange ROOTPE_CPL=512 > xmlchange NTASKS_GLC=320 > xmlchange NTHRDS_GLC=1 > xmlchange ROOTPE_GLC=0 > xmlchange NTASKS_ICE=320 > xmlchange NTHRDS_ICE=1 > xmlchange ROOTPE_ICE=0 > xmlchange NTASKS_LND=192 > xmlchange NTHRDS_LND=2 > xmlchange ROOTPE_LND=320 > xmlchange NTASKS_OCN=64 > xmlchange NTHRDS_OCN=1 > xmlchange ROOTPE_OCN=832 > xmlchange NTASKS_ROF=192 > xmlchange NTHRDS_ROF=2 > xmlchange ROOTPE_ROF=320 > ./cesm_setup |
It is interesting to compare the timings from the 128- and 1728-processor runs. The timing output below shows that the original model run on 128 pes cost 851 pe-hours/simulated_year. Running on 1728 pes, the model cost more than 5 times as much, but it runs more than two and a half times faster.
128-processor case: Overall Metrics: Model Cost: 851.05 pe-hrs/simulated_year (scale= 1.00) Model Throughput: 3.61 simulated_years/day 1728-processor case: Overall Metrics: Model Cost: 4439.16 pe-hrs/simulated_year (scale= 1.00) Model Throughput: 9.34 simulated_years/day |
See understanding load balancing CESM for detailed information on understanding timing files.