CESM Overview
The Community Earth System Model (CESM) is a coupled climate model for simulating Earth's climate system. Composed of five separate models simultaneously simulating the Earth's atmosphere, ocean, land, land-ice, and sea-ice, plus one central coupler component, CESM allows researchers to conduct fundamental research into the Earth's past, present, and future climate states.
The CESM system can be configured a number of different ways from both a science and technical perspective. CESM supports several different resolutions and component configurations. In addition, each model component has input options to configure specific model physics and parameterizations. CESM can be run on a number of different hardware platforms and has a relatively flexible design with respect to processor layout of components. CESM also supports both an internally developed set of component interfaces and the ESMF compliant component interfaces (See the Section called Use of an Earth System Modeling Framework (ESMF) library and ESMF interfaces in Chapter 9)
The CESM project is a cooperative effort among U.S. climate researchers. Primarily supported by the National Science Foundation (NSF) and centered at the National Center for Atmospheric Research (NCAR) in Boulder, Colorado, the CESM project enjoys close collaborations with the U.S. Department of Energy and the National Aeronautics and Space Administration. Scientific development of the CESM is guided by the CESM working groups, which meet twice a year. The main CESM workshop is held each year in June to showcase results from the various working groups and coordinate future CESM developments among the working groups. The CESM website provides more information on the CESM project, such as the management structure, the scientific working groups, downloadable source code, and online archives of data from previous CESM experiments.
CESM Software/Operating System Prerequisites
The following are the external system and software requirements for installing and running CESM1.0.
UNIX like operating system (LINUX, AIX, OSX)
csh, sh, perl, and xml scripting languages
subversion client version 1.6.11 or greater
Fortran 90 and C compilers. pgi, intel, and xlf are recommended options.
MPI (although CESM does not absolutely require it for running on one processor only)
Earth System Modeling Framework (ESMF) (optional) 5.2.0p1
pnetcdf (optional) 1.1.1 or newer
The following table contains the version in use at the time of release. These versions are known to work at the time of the release for the specified hardware.
Table 1-1. Recommmended Software Package Versions by Machine
| Machine | Version Recommendations |
|---|---|
| Cray XT Series | pgf95 9.0.4, pgcc 10.2, MPT3.5.1 |
| IBM Power Series | xlf 12.1, xlC 10.1 |
| IBM Bluegene/P | xlf 11.1, xlC 9.0 |
| Generic Linux Machine | ifort (intel64) 10.1.018, icc 10.1.018, openmpi 1.2.8 |
Note: CESM may not compile with pgi compilers prior to release 9.0.x. PGI Fortran Version 7.2.5 aborts with an internal compiler error when compiling CESM1.0, specifically POP.
| Caution |
NetCDF must be built with the same Fortran compiler as CESM. In the netCDF build the FC environment variable specifies which Fortran compiler to use. CESM is written mostly in Fortran, netCDF is written in C. Because there is no standard way to call a C program from a Fortran program, the Fortran to C layer between CESM and netCDF will vary depending on which Fortran compiler you use for CESM. When a function in the netCDF library is called from a Fortran application, the netCDF Fortran API calls the netCDF C library. If you do not use the same compiler to build netCDF and CESM you will in most cases get errors from netCDF saying certain netCDF functions cannot be found. |
Parallel-netCDF, also referred to as pnetcdf, is optional. If a user chooses to use pnetcdf, version 1.1.1. or later should be used with CESM1.0. It is a library that is file-format compatible with netCDF, and provides higher performance by using MPI-IO. Pnetcdf is turned on inside pio by setting the PNETCDF_PATH variable in the pio CONFIG_ARGS in the Macros.$MACH file. You must also specify that you want pnetcdf at runtime via the io_type argument that can be set to either "netcdf" or "pnetcdf" for each component.
CESM Components
CESM consists of five geophysical models: atmosphere (atm), sea-ice (ice), land (lnd), ocean (ocn), and land-ice (glc), plus a coupler (cpl) that coordinates the models and passes information between them. Each model may have "active," "data," "dead," or "stub" component version allowing for a variety of "plug and play" combinations.
During the course of a CESM run, the model components integrate forward in time, periodically stopping to exchange information with the coupler. The coupler meanwhile receives fields from the component models, computes, maps, and merges this information, then sends the fields back to the component models. The coupler brokers this sequence of communication interchanges and manages the overall time progression of the coupled system. A CESM component set is comprised of six components: one component from each model (atm, lnd, ocn, ice, and glc) plus the coupler. Model components are written primarily in Fortran 90.
The active (dynamical) components are generally fully prognostic, and they are state-of-the-art climate prediction and analysis tools. Because the active models are relatively expensive to run, data models that cycle input data are included for testing, spin-up, and model parameterization development. The dead components generate scientifically invalid data and exist only to support technical system testing. The dead components must all be run together and should never be combined with any active or data versions of models. Stub components exist only to satisfy interface requirements when the component is not needed for the model configuration (e.g., the active land component forced with atmospheric data does not need ice, ocn, or glc components, so ice, ocn, and glc stubs are used).
The CESM components can be summarized as follows:
| Model Type | Model Name | Component Name | Type | Description |
|---|---|---|---|---|
| atmosphere | atm | cam | active | The Community Atmosphere Model (CAM) is a global atmospheric general circulation model developed from the NCAR CCM3. |
| atmosphere | atm | datm | data | The data atmosphere component is a pure data component that reads in atmospheric forcing data |
| atmosphere | atm | xatm | dead | |
| atmosphere | atm | satm | stub | |
| land | lnd | clm | active | The Community Land Model (CLM) is the result of a collaborative project between scientists in the Terrestrial Sciences Section of the Climate and Global Dynamics Division (CGD) at NCAR and the CESM Land Model Working Group. Other principal working groups that also contribute to the CLM are Biogeochemistry, Paleoclimate, and Climate Change and Assessment. |
| land | lnd | dlnd | data | The data land component differs from the other data models in that it can run as a purely data-runoff model (reading in runoff data) or as a purely data-land model (reading in coupler history data for atm/land fluxes and land albedos produced by a previous run) or both. |
| land | lnd | xlnd | dead | |
| land | lnd | slnd | stub | |
| ocean | ocn | pop | active | The ocean model is an extension of the Parallel Ocean Program (POP) Version 2 from Los Alamos National Laboratory (LANL). |
| ocean | ocn | docn | data | The data ocean component has two distinct modes of operation. It can run as a pure data model, reading ocean SSTs (normally climatological) from input datasets, interpolating in space and time, and then passing these to the coupler. Alternatively, docn can compute updated SSTs based on a slab ocean model where bottom ocean heat flux convergence and boundary layer depths are read in and used with the atmosphere/ocean and ice/ocean fluxes obtained from the coupler. |
| ocean | ocn | xocn | dead | |
| ocean | ocn | socn | stub | |
| sea-ice | ice | cice | active | The sea-ice component (CICE) is an extension of the Los Alamos National Laboratory (LANL) sea-ice model and was developed though collaboration within the CESM Polar Climate Working Group (PCWG). In CESM, CICE can run as a fully prognostic component or in prescribed mode where ice coverage (normally climatological) is read in. |
| sea-ice | ice | dice | data | The data ice component is a partially prognostic model. The model reads in ice coverage and receives atmospheric forcing from the coupler, and then it calculates the ice/atmosphere and ice/ocean fluxes. The data ice component acts very similarly to CICE running in prescribed mode. |
| sea-ice | ice | xice | dead | |
| sea-ice | ice | sice | stub | |
| land-ice | glc | cism | active | The CISM component is an extension of the Glimmer ice sheet model. |
| land-ice | glc | sglc | stub | |
| coupler | cpl | cpl | active | The CCSM4/CESM1 coupler was built primarily through a collaboration of the NCAR CESM Software Engineering Group and the Argonne National Laboratory (ANL). The MCT coupling library provides much of the infrastructure. cpl7 is used in CCSM4 and CESM1 and is technically a completely new driver and coupler compared to CCSM3. |
CESM Component Sets
The CESM components can be combined in numerous ways to carry out various scientific or software experiments. A particular mix of components, along with component-specific configuration and/or namelist settings is called a component set or "compset." CESM has a shorthand naming convention for component sets that are supported out-of-the-box.
The compset name usually has a well defined first letter followed by some characters that are indicative of the configuration setup. Each compset name has a corresponding short name. Users are not limited to the predefined component set combinations. A user may define their own component set.
See the component set table for a complete list of supported compset options. Running create_newcase with the option "-list" will also always provide a listing of the supported out-of-the-box component sets for the local version of CESM1. In general, the first letter of a compset name indicates which components are used. An exception to this rule is the use of "G" as a second letter to indicate use of the active glc model, CISM. The list of first letters and their corresponding component sets each denotes appears below:
| Designation | Components | Details |
|---|---|---|
| A | datm,dlnd,dice,docn,sglc | All DATA components with stub glc (used primarily for testing) |
| B | cam,clm,cice,pop2,sglc | FULLY ACTIVE components with stub glc |
| C | datm,dlnd,dice,pop2,sglc | POP active with data atm, lnd(runoff), and ice plus stub glc |
| D | datm,slnd,cice,docn,sglc | CICE active with data atm and ocean plus stub land and glc |
| E | cam,clm,cice,docn,sglc | CAM, CLM, and CICE active with data ocean (som mode) plus stub glc |
| F | cam,clm,cice,docn,sglc | CAM, CLM, and CICE(prescribed mode) active with data ocean (sstdata mode) plus stub glc |
| G | datm,dlnd,cice,pop2,sglc | POP and CICE active with data atm and lnd(runoff) plus stub glc |
| H | datm,slnd,cice,pop2,sglc | POP and CICE active with data atm and stub land and glc |
| I | datm,clm,sice,socn,sglc | CLM active with data atm and stub ice, ocean, and glc |
| S | satm,slnd,sice,socn,sglc | All STUB components (used for testing only) |
| X | xatm,xlnd,xice,xocn,sglc | All DEAD components except for stub glc (used for testing only) |
CESM Grids
The grids are specified in CESM1 by setting an overall model resolution. Once the overall model resolution in set, components will read in appropriate grids files and the coupler will read in appropriate mapping weights files. Coupler mapping weights are always generated externally in CESM1. The components will send the grid data to the coupler at initialization, and the coupler will check that the component grids are consistent with each other and with the mapping weights files.
In CESM1, the ocean and ice must be on the same grid, but unlike CCSM3, the atmosphere and land can now be on different grids. Each component determines its own unique grid decomposition based upon the total number of pes assigned to that component.
CESM1 supports several types of grids out-of-the-box including single point, finite volume, spectral, cubed sphere, displaced pole, and tripole. These grids are used internally by the models. Input datasets are usually on the same grid but in some cases, they can be interpolated from regular lon/lat grids in the data models. The finite volume and spectral grids are generally associated with atmosphere and land models but the data ocean and data ice models are also supported on those grids. The cubed sphere grid is used only by the active atmosphere model, cam. And the displaced pole and tripole grids are used by the ocean and ice models. Not every grid can be run by every component.
CESM1 has a specific naming convention for individual grids as well as the overall resolution. The grids are named as follows:
"[dlat]x[dlon]" are regular lon/lat finite volume grids where dlat and dlon are the approximate grid spacing. The shorthand convention is "fnn" where nn is generally a pair of numbers indicating the resolution. An example is 1.9x2.5 or f19 for the approximately "2-degree" finite volume grid. Note that CAM uses an [nlat]x[nlon] naming convection internally for this grid.
"Tnn" are spectral lon/lat grids where nn is the spectral truncation value for the resolution. The shorthand name is identical. An example is T85.
"ne[X]np[Y]" are cubed sphere resolutions where X and Y are integers. The short name is generally ne[X]. An example is ne30np4 or ne30.
"pt1" is a single grid point.
"gx[D]v[n]" is a displaced pole grid where D is the approximate resolution in degrees and n is the grid version. The short name is generally g[D][n]. An example is gx1v6 or g16 for a grid of approximately 1-degree resolution.
"tx[D]v[n]" is a tripole grid where D is the approximate resolution in degrees and n is the grid version. The short name is [agrid]_[lgrid]_[oigrid]. An example is ne30_f19_g16.
The model resolution is specified by setting a combination of these resolutions. In general, the overall resolution is specified in one of the two following ways for resolutions where the atmosphere and land grids are identical or not.
- "[algrid]_[oigrid]"
In this grid, the atmosphere and land grid are identical and specified by the value of "algrid". The ice and ocean grids are always identical and specified by "oigrid". For instance, f19_g16 is the finite volume 1.9x2.5 grid for the atmosphere and land components combined with the gx1v6 displaced pole grid for the ocean and ice components.
- "[agrid]_[lgrid]_[oigrid]" or "[agrid][lgrid]_[oigrid]" (for short names)
In this case, the atmosphere, land, and ocean/ice grids are all unique. For example ne30_f19_g16 is the cubed sphere ne30np4 atmospheric grid running with the finite volume 1.9x2.5 grid for the land model combined with the gx1v6 displaced pole grid running on the ocean and ice models.
For a complete list of currently supported grid resolutions, please see the supported resolutions table.
The ocean and ice models run on either a Greenland dipole or a tripole grid (see figures). The Greenland Pole grid is a latitude/longitude grid, with the North Pole displaced over Greenland to avoid singularity problems in the ocn and ice models. Similarly, the Poseidon tripole grid (http://climate.lanl.gov/Models/POP/ ) is a latitude/longitude grid with three poles that are all centered over land.
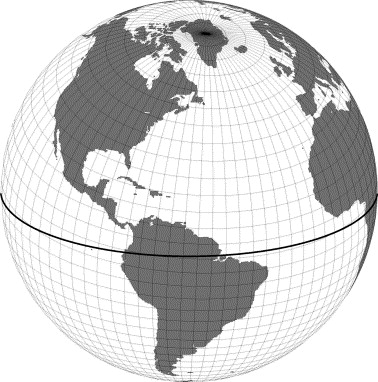
Greenland Pole Grid
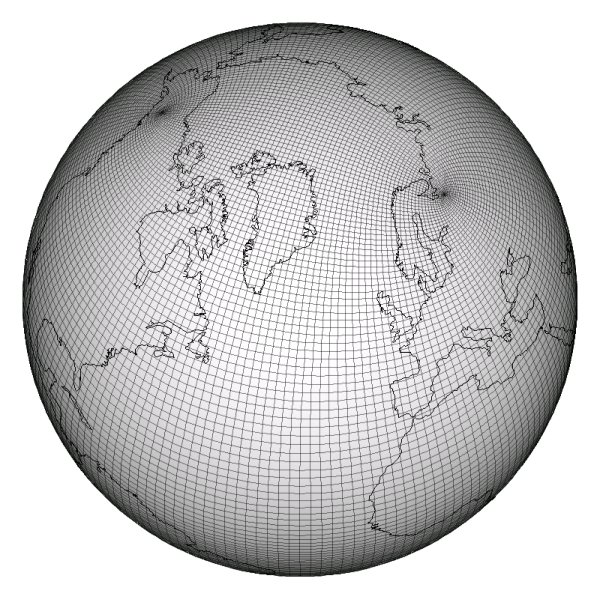
Poseidon Tripole Grid
CESM Machines
Scripts for supported machines, prototype machines and generic machines are provided with the CESM1 release. Supported machines have machine specific files and settings added to the CESM1 scripts and are machines that should run CESM cases out-of-the-box. Machines are supported in CESM on an individual basis and are usually listed by their common site-specific name. To get a machine ported and functionally supported in CESM, local batch, run, environment, and compiler information must be configured in the CESM scripts. Prototype machines are machines in the CESM user community that CESM has been ported to and the machine specific files and settings were provided by the user community. Prototype machines all start with the prefix prototype_. These machines may not work out-of-the-box, however, to the best of NCAR's knowledge these machine specific files and settings worked at one time. Generic machine generally refers more to classes of machines, like IBM AIX or a linux cluster with an intel compiler, and the generic machine names in CESM1 all start with the generic_ prefix. Generic machines require that a user provide some settings via command line options with create_newcase and then some additional effort will generally be required to get the case running. Generic machines are handy for quickly getting a case running on a new platform, and they also can accelerate the porting process. For more information on porting, see Chapter 7. To get a list of current machines in each of these categories (supported, prototype and generic) run script create_newcase with option -list from the $CCSMROOT directory.
The list of available machines are documented in CESM machines . Running create_newcase with the "-list" option will also show the list of available machines for the current local version of CESM1. Supported machines have undergone the full CESM porting process. A prototype machine is provided by the user community and may not work out-of-the-box, but it is a good starting point for a port to a new machine of the same type. A generic machine is provided as a starting point for new users to introduce a machine that does not belong to any of the above categories. The machines available in each of these categories changes as access to machines change over time.
CESM Validation
Although CESM1.0 can be run out-of-the-box for a variety of resolutions, component combinations, and machines, MOST combinations of component sets, resolutions, and machines have not undergone rigorous scientific climate validation.
Long control runs are being carried out, and these will be documented in future versions of this guide, located at http://www.cesm.ucar.edu/models/cesm1.0. Model output from these long control runs will accompany future releases, and these control runs should be scientifically reproducible on the original platform or other platforms. Bit-for-bit reproducibility cannot be guaranteed due to variations in compiler or system versions.
Users should carry out your own validations on any platform prior to doing scientific runs or scientific analysis and documentation.